Source: Youtube 모두를 위한 RL강좌 - Sung Kim
www.youtube.com/playlist?list=PLlMkM4tgfjnKsCWav-Z2F-MMFRx-2gMGG
Lecutre 3: Q-Learning (Table)
Policy using Q-function
Max Q = maxQ(s1, a): Q 형님이 가질 수 있는 Rewards 중 제일 높은 값
π*(s) = argmaxQ(s1, a): Q 형님이 가질 수 있는 Rewards 중 제일 높은 값이 있는 Action
Assum (belive) Q in s' exist
The Condition
- I am in s
- When I do action a, I will go to s' & get reward r
- Q in s', Q(s', a') exist
Thus,
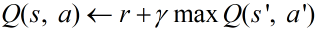
Q 형님이 여러가지 방향을 탐험하게 해주는 것 ε-greedy
Thust,

Lecutre 5: Deterministic World vs Stochastic World (nondeterministic)
Deterministic: 결정된 Action대로 Q 형님의 State 결정됨
Stochastic: Right Action 명령했지만 Q 형님 맘대로 State 결정됨, 하지만 Q 형님은 Right Action 했다고 입력됨
Thus, 한 곳의 Action Reward만 고려하는 것이 아닌, 여러 방향의 Action을 고려해야함.
이를 수식으로 표현하고자 α(Learning Rate) 개념 등장
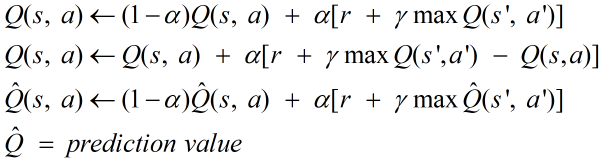
Lecutre 6: Q-Network
Q-Table처럼 Q Function이 소규모이지 않기 때문에 등장한 개념
Q-Network에서 ANN을 업데이트할 때는 경사하강법을 사용
경사하강법을 사용해 ANN을 업데이트하려면 오차함수 정의 필요
오차함수는 가장 기본적으로 MSE(Mean Squared Error) 사용

ε-greedy 통하여 Random Action(At) or maxQ를 선택함

Loss Function을 최소화(Gradient Descent)하는 값을 찾아서
Prediction Value Q ≒ Optimal Q을 만드는 것이 목표(Q-Table에서는 가능, Q-Network에서는 불가능)

Lecutre 7: DQN
Q Network Loss Function 적용시 2가지 문제점 발생

근단적으로 설명시, 아주 근접한 Sample을 선택하게 될경우 Optimal과는 완전 다른 형태가 Prediction됨
이를 방지하고자 D라는 Buffer에 Data들을 저장후, Random하게 Data를 호출하여 Optimal Prediction 진행


Loss Function에서 Target과 Prediction의 Θ Network를 따로 생성(Network가 2개)
Prediction의 Θ'이 Target의 Θ와 적합하도록 처리한 후 나중에 Θ'=Θ로 같게 복사함
위 2번 식의 근본적인 목적은 Weight 최소화 하기

'둘 > [ Machine Learning ]' 카테고리의 다른 글
| [GAN] 오토인코더와 GAN을 사용한 표현 학습과 생성적 학습 (0) | 2021.01.26 |
|---|---|
| [Reinforcement Learning] Pang-Yo Lab (0) | 2021.01.15 |
| [Reinforcement Learning] RL Concepts (0) | 2021.01.12 |
| [PyTorch] PyTorch 설치 (0) | 2021.01.07 |
| DataFrame 엑셀(xlsx, csv) 파일 형식으로 저장하기 (0) | 2021.01.06 |



